Chapter 1 - Planning a Puppet Infrastructure
When designing a Puppet implementation, we immediately encounter a vast array of possible options, so it’s crucial to identify requirements before doing anything else. This helps to focus attention on what is actually needed, rather than what is possible.
Anyone following this guide should end up with the following cool features:
- Automated host commissioning (Linux on VMware)
- Centralised configuration management (Puppet Enterprise)
- Hierarchical configuration (Hiera)
- Version controled Puppet code (Git)
- Support for Dynamic Environments
- Puppet code organised into Roles and Profiles
Puppet Enterprise (PE) has been selected as the configuration management system because of the official support available. We should be able to satisfy the above requirements with an out-of-the-box PE installation and a couple of our own scripts.
Design Considerations
There are some additional questions which we had to answer before any installation could proceed. This is a summary of those questions and the answers we settled upon.
Q: How many Puppet installations are required?
A: Start with one installation for non-prod, and review when more experience has been gained. Adding an additional environment for production should then be trivial, if it’s required.
Q: Is an additional Puppet Master server required for HA?
If the master is virtualised, and the platform is considered robust, then additional master servers should not be required. Scaling would be achieved by increasing resources allocated to the single host.
This decision affects the architecture; using more than one Puppet Master requires the use of a separate Certificate Authority (CA).
A: We concluded that one Puppet Master (per installation) is likely to be sufficient.
Q: Is any additional software required?
It’s possible to use additional software to provide extra functionality. For example, Foreman provides Puppet management, automated server provisioning, agent control, report management and more, all via a graphical user interface.
However, some of Foreman’s features are already provided by PE’s dashboard, and autoprovisioning is available using PE command line tools. Foreman also adds a large amount of complexity to the installation procedure, which may hinder progress.
Integrating many different software products can get very complex very quickly. It’s important to gain experience with Puppet Enterprise itself before trying to shoehorn other software into the mix. If we eventually find that PE lacks some critical functionality, then other options may be considered.
A: Start with Puppet Enterprise only. No additional software.
Ingredients
Based on the decisions above, the initial Puppet environment will consist of:
- 1 x Puppet Enterprise Puppet Master with Hiera-based configuration
- 1 x Puppet Enterprise console server with Cloud Provisioner
- 1 x PuppetDB server
- A local Git repository for Puppet configuration
- A VMware platform (VMware vSphere >= 4.0 and VMware vCenter)
The resulting platform is illustrated in this diagram:
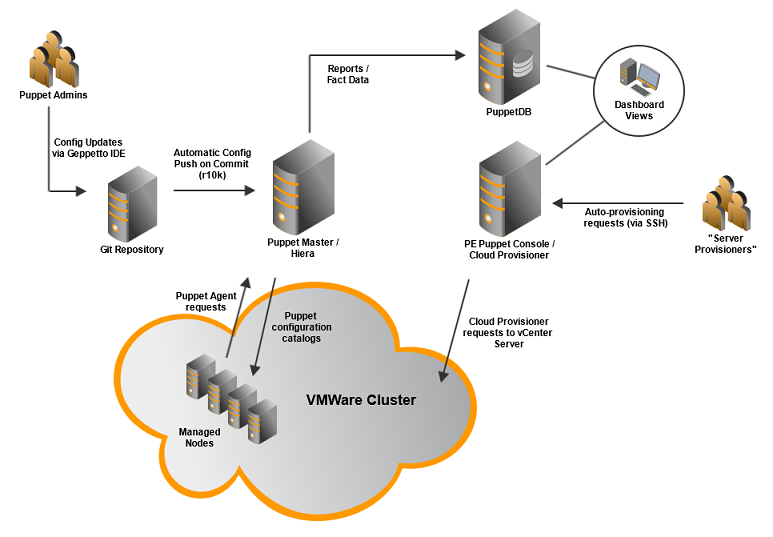
We aim to make the platform flexible enough to address current requirements without becoming over-complicated; keeping complexity to a minimum makes it easier to manage, support and extend.
Note that Cloud Provisioner also supports AWS EC2, so in theory, auto-provisioning Amazon EC2 instances will require minimal additional effort.
High-Level Implementation Tasks
Also based on the answers to our questions above, the high-level implementation tasks will be as follows:
- Install the Puppet Enterprise platform.
- Create a basic Hiera-based configuration.
- Configure and test Cloud Provisioner.
- Use what we have so far to try and create a realistic environment.
- Create a Git repository for Puppet configuration.
- Devise a plan for bringing existing hosts under Puppet control.
Note how these tasks correspond roughly to the chapters in this book? No coincidence there! We’ll have a quick overview of all these tasks, before giving each one its own dedicated chapter…
1. PE Platform Installation
We can split this into a number of sub-tasks:
- Identify or create three new CentOS 6 VMs.
- Install Puppet Master, Console and PuppetDB.
- Install Cloud Provisioner on the Console server.
- Document the installation.
Once these are done we should have a fully functioning Puppet Enterprise installation, complete with a record of how it came into existence. It won’t do anything until we configure it though.
Dedicated Chapter:
The installation is documented here:
2. Basic Hiera-based Configuration
Heira simplifies Puppet configuration by separating node configuration data from the Puppet code. It also allows hierarchical node configuration, which makes it easier to configure overrides and exceptions. Hiera is included in Puppet Enterprise 3.x.
Before we start creating Puppet Agents and pointing them at the Puppet Master, we will create a basic configuration with some class and group definitions. This will help with the next step - Auto-provisioning.
Of course, Puppet configuration is an on-going iterative process, so anything created at this point will be repeatedly revised and explored as we proceed with the next steps.
Dedicated Chapter:
3. Configure and Test Cloud Provisioner
This is Puppet’s auto-provisioning mechanism for cloud systems. It’s a suite of command line tools which uses the “Fog” Ruby cloud services library. It’s image-based, so doesn’t use the PXE/DHCP/TFTP bootstrap approach normally associated with bare-metal provisioning.
Puppet Enterprise Cloud Provisioner currently supports the following virtualisation and cloud platforms:
- VMware
- Amazon EC2
- Google Compute Engine
- OpenStack
Since we have access to an existing VMware platform, that’s what we’ll be focusing on.
Sub-tasks:
- Set up VMware authentication credentials on the Cloud Provisioner server.
- Identify or create a minimal “standard build” VMware template.
- Test VM creation, puppet agent install and automated certificate signing.
- Test end-to-end automation of this process.
- Document the configuration and findings.
When it comes to VM templates, a couple of questions spring to mind:
- Should the standard template have the puppet agent already installed and configured?
- Should it be a minimal build, allowing puppet to bring it up to speed for a particular server role, or should different role- dependent standard builds be utilised?
We decided to use a minimal build without a puppet agent, allowing the puppet agent to be installed as part of the provisioning process. The agent would then be responsible for configuring the machine accordingly.
Clearly this will be more time-consuming than provisioning pre-configured VM templates, but should result in a smaller number of templates to maintain, and therefore a less complex provisioning process.
Dedicated Chapter:
4. Testing - Create a New Development Environment
At this point, we may want to destroy any VMs created so far and start moving towards a real-world scenario.
- Define the target environment (e.g. 2 web servers, 2 app servers and a db server)
- Configure puppet with appropriate groups for each type of server.
- Use Cloud Provisioner to create the new VMs, and test that everything works as expected.
- Develop a script to create the environment in one command.
First attempts at this will probably result in a non-functioning environment. The aim would be to improve the Puppet configuration incrementally to the point where these servers become fully functional, then tear them down and try re-creating the environment automatically. A test plan should be created to track this activity.
During this process we learn a lot about writing Puppet code, and in fact this is where you’ll have most of the fun, but as it’s an organisation-specific exercise which doesn’t relate to setting up the platform per se, we’ll not give it a dedicated chapter in this book.
5. Managing the Puppet Configuration using Git
A local Git repository will be used to manage the Puppet configuration. This provides various benefits, including:
- Configuration auditing and change tracking.
- The ability to easily identify and roll back changes.
- Restoration of the Puppet Master in the event of an unrecoverable failure.
- Using post-update hooks, the Git server is able to automatically deploy any committed changes to the Puppet Master.
Access to the git repository will be controlled using gitolite.
Dedicated Chapter:
6. Bring Existing Hosts Under Puppet Control
Further planning is required to start using Puppet “in the wild”. Once the platform is up and running as described in this document, with suitable operating procedures defined, then the existing estate may be brought under Puppet control. The implementation roll-out plan may or may not be addressed in a separate document. Cryptic, eh?
Dedicated Chapter:
Further Reading
- Installing Puppet Enterprise
- Heira Documentation
- PE Cloud Provisioner Docs
- GitHub page for Fog
- VMware Documentation - Working With Templates And Clones
- VMware Hands-on Labs - Provisioning VMs with Puppet
- Gitolite Documentation
- Scalable Dynamic Environments with Git and r10k
Next…
Forging on, we’ll take a look at the easy steps required to install our Puppet Enterprise platform.